

Elasticsearch has become ubiquitous and can be found in organizations of all sizes. However, optimizing Elasticsearch isn’t just a science; it’s an art. This is because performance metrics are uniquely influenced by the type of data being ingested.
I have managed some fairly large Elasticsearch clusters for several organizations. I have employed the following principles to keep Elasticsearch clusters up and running fast.
Core Principles for Maintaining a Fast ElasticSearch Cluster
Heap Size Management
Proper configuration of the JVM heap size is crucial. It’s recommended to allocate no more than 50% of the available memory to the Elasticsearch heap while ensuring that the heap size is enough to manage the cluster’s workload. Do not exceed 32GB, as going too large can lead to slowdowns as well.
Leverage Datastreams when possible
Datastreams are your friends, especially when dealing with time-based data. They simplify index creation and management, making your data handling much more efficient.
Monitoring and Performance Tuning
Here’s a non-negotiable: regular monitoring of your cluster’s health and performance metrics. Tools like Prometheus, coupled with the Elasticsearch exporter, are invaluable in this regard. Neglecting monitoring is a perilous path, as Elasticsearch can be finicky, and performance issues tend to accumulate stealthily over time. I typically use Prometheus with the Elasticsearch exporter.
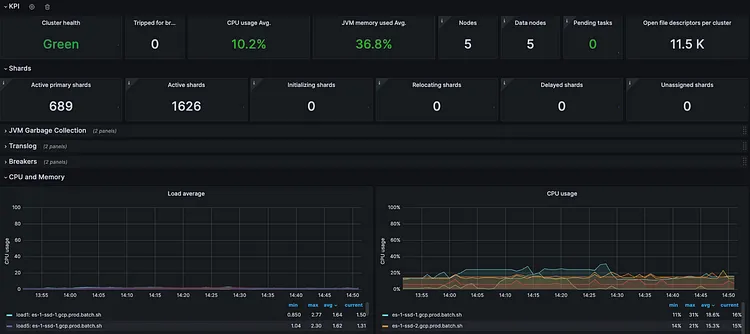
Prometheus Monitor
Correctly size shards based on the cluster
Shard sizing is more art than science. There’s no one-size-fits-all answer, but experience suggests that shards in the 10GB to 50GB range generally yield good results for logs and time series data. Play with adjusting these and review your metrics to see how your query/index times are affected.
Create lifecycle policies
Automate the management of your index lifecycle. This involves setting up phases for the creation, aging, and deletion of indices, thereby optimizing both storage and data accessibility.
Engage with us!
Join the conversation, share your ideas, and collaborate with a diverse and passionate community.

A Deeper Dive: Data Efficiency
One of the most important strategies involves meticulous data management — specifically, dropping unnecessary data, reducing the number of fields, and minimizing field sizes. This approach is crucial for maintaining a lean and efficient Elasticsearch cluster. It’s akin to decluttering your digital environment, which significantly enhances performance by simplifying the search and retrieval processes.
Streamdal Log Processor Integration
We will cover using open-source Streamdal and its log processor to accomplish these goals. But, you can probably implement similar functionality by manually using log stash’s log filters. By using Streamdal’s log processor with our LogStash agent, we tap into a suite of functions designed for efficient data analysis and transformation. This integration ensures that the data landing in Elasticsearch is already processed, optimized, and ready for efficient storage and retrieval. See my other blog post Super LogStash with PII Rules for more info on how to set up/additional features.
Data Management: Game Plan
Let’s look at a sample log entry and come up with a plan to keep our Elasticsearch running fast.
{
"timestamp": "2024-02-12T14:46:25Z",
"user_id": 77,
"activity": "view",
"details": {
"ip_address": "192.168.1.166",
"location": "Germany",
"email": "[email protected]",
"phone": "+1-967-510-7714",
"long_field": "vna6EnpbOajYeUCMjKH5DgngCYYwPJo9MCKCjfd16d0mKuSNzbkWvm0WhAXDYOWkaJcGjQJjz9wbOglX6943d8GbkabSvV7KdGzOadMoEaR4C85eKcOAUTZoYa2MU4wwAh6lP9j5muYLBxoGFfxxhZ4ugw45DoFHVHIqm001NgsNFrMvFkrqkqWjU5pr44JougBqwgud1FF6FVBG12qIncTBPietYG9c6SOtDpPuIoBQD7WpAAmLuJYajsuaXjghGzCJ1PGuop1GorubJ4ihgiYNIpV6KLniNNwA7CL2DbAMRBCDGWEDcnYWtwr1syiwhfSj5KXhl8Xj46AkwDowMUq3NJXLDL7zY34ML15ETZRRPcyURjWCbb8Uq8BoGvt0s2M0TS9Zd7G0L8l7fLi3XcUSaLadVjDWBbH33KJpvOEMisTFugXjIb9k0LysmPovGTSmNOxxjr5mW6gKY7Tshb2z9s8kfvcrwPVzEXwYuUwT2IPwGo8pIVNhdhfQmb6l884wAGWrgzhut2WuXP8xmR2dNXFHBKMjUBApT5YDzgsLq6J8C2NLxAod2YLD7lPG9Jjia6WcJt0fk1MtHQgjKrtehKk0bCtzeOHFiICMoXkLap9I2xrEx8SJ6vA94o5tEL8seFcWh1OxxFyzVizAnIrNIziISSvEFinhH56acYcZoojLarWEH52JycGQdED2bBiNRrWUxQvYYfzuywue09FJD8ZjqZmIrpTuY7zfBVeygS0TWwolmz74JEO8exSGm9mgTUmVSLvczYtFBtFG7F2I30Yjx41AUAXJ54s2GLQfIrGmP5sMS2vmE7DZCXtVDWdL0hdkszHrS5AesndfRGDLj901nlIoe646tkGcxMGEHOMNsTxDLUUzyqm8pabKf191Jeu2AVJaySBL8GVjGwyKY5pPiIafQltZzyvBlkIWlW5dsSXr9ADYENir1EVXlaSwloqjCnbvhUtakShT92VnvldoOgAtHmpH2QtmgllmqBCbdSP502Hy8QA26UHV",
"product_color": "red",
"product_size": "large",
"irrelevant_field": "This field is not relevant to the app"
},
"is_e2e_test_account": false
}We will now create a series of pipelines to remove any unnecessary data. When completed we will have a much more sustainable stream of logs.
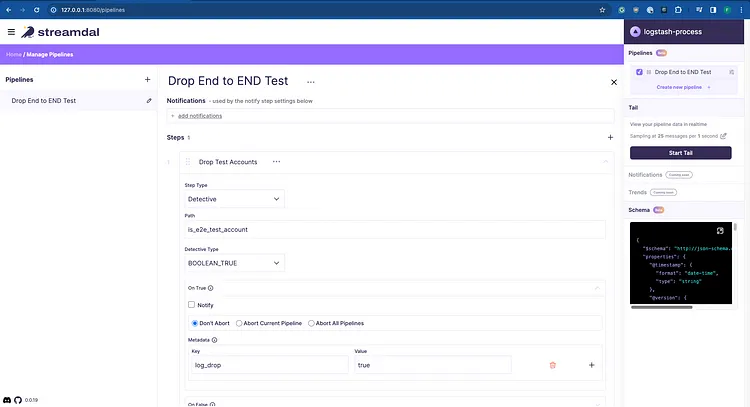
Dropping Test and Development Data
In our example log, there is a field called ‘is_e2e_test_account’ with value either true or false. This indicates the message is a test from our internal systems. We have no reason to log these to our Elasticsearch, so let’s find all instances where the value equals true and set metadata that instructs our log-processor to drop them.
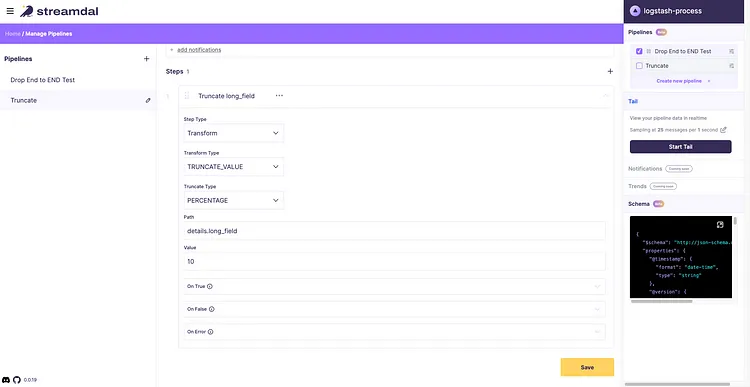
Truncating Large Field Values
In the example event, we will now truncate the value under the key ‘long_field’. As you can see it’s a very verbose value and our application does not need the full value.
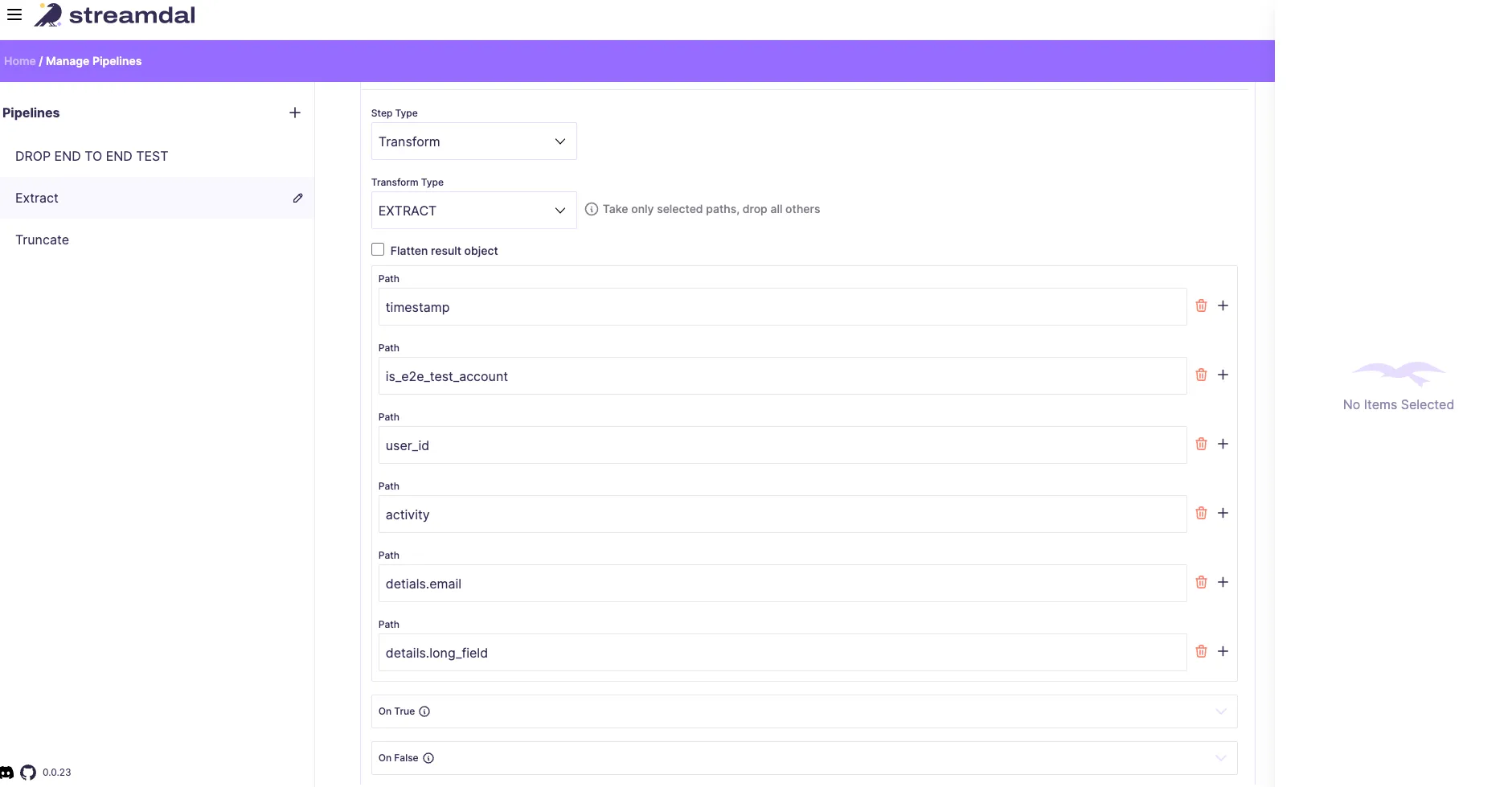
Keeping Only Necessary Fields
Streamdal’s ‘Extract fields’ step is a powerful tool for streamlining our data. It allows us to selectively keep only the essential fields in our JSON data, effectively dropping any unnecessary or redundant information.
Game Plan Results:
Before we dropped test data, about 20% of all data saved to Elasticsearch was from our e2e test account.
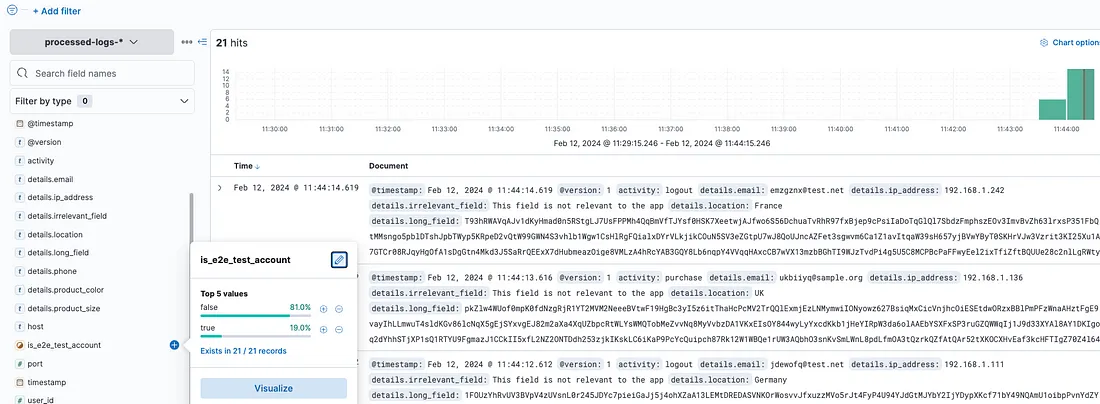
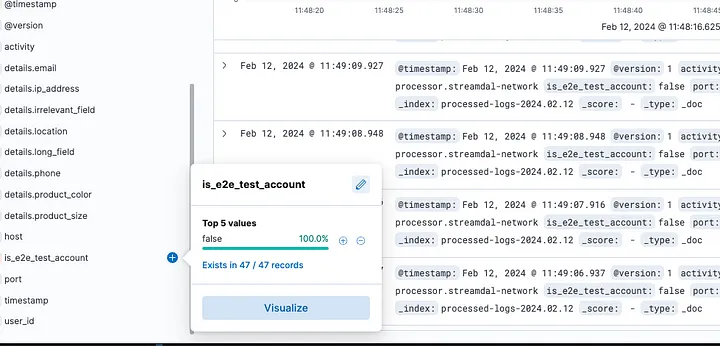
After we applied our pipeline, all test data dropped off.
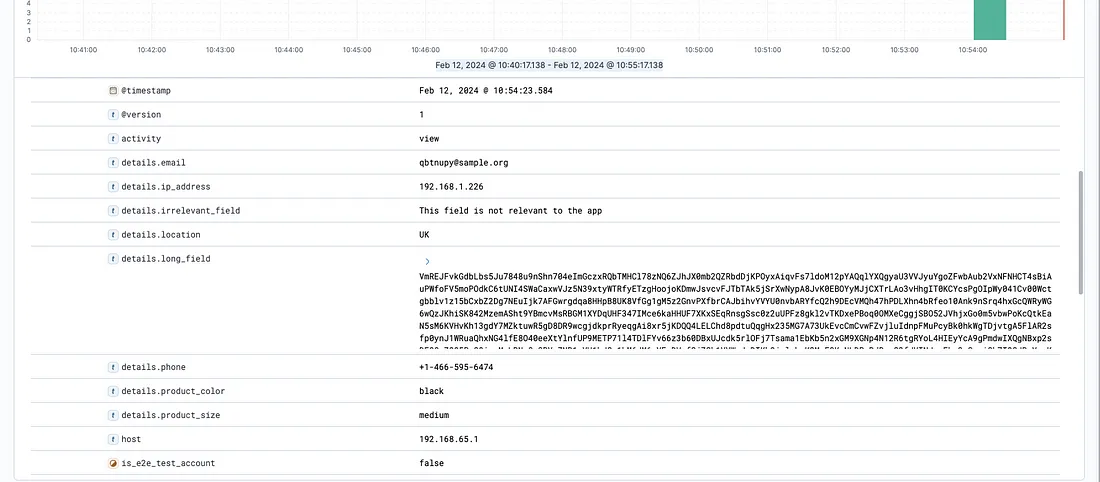
Our Elasticsearch had a bunch of extra fields and a large unnecessary field value.
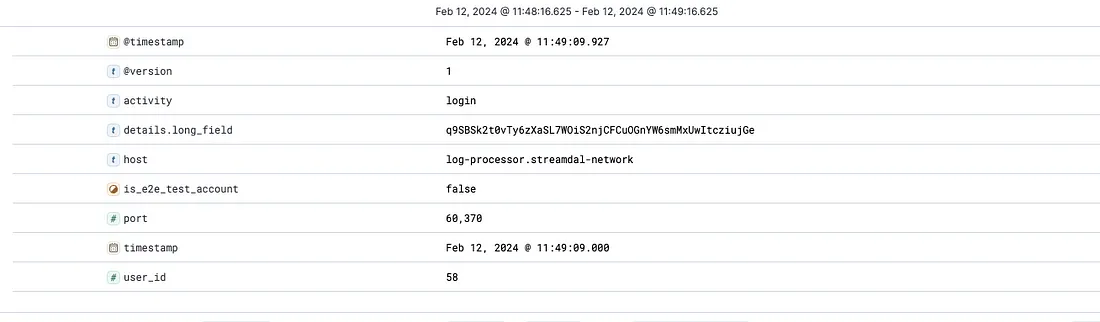
Now we have extracted the fields we care about, and truncated unnecessarily long field bodies.
Conclusion: Elevating Elasticsearch Performance
The key to a high-performing Elasticsearch cluster lies in a blend of configuration and smart data management. By managing heap sizes, leveraging data streams, conducting regular performance monitoring, sizing shards appropriately, creating lifecycle policies, and optimizing data processing with Streamdal, we not only enhance the speed and efficiency of our clusters but also ensure their scalability and resilience.
Following these principles should keep your Elasticsearch running fast and avoid performance trending down over time.

Want to nerd out with me and other misfits about your experiences with monorepos, deep-tech, or anything engineering-related?
Join our Discord, we’d love to have you!



