

We love our gorgeous UI and we know you will too. However, we understand that manually configuring all your pipelines can be a daunting task at scale. We’ve created a Terraform provider to help. This blog will show you how to quickly get a pipeline up and running with our Terraform provider.
Why Terraform?
As the current industry leader, Terraform was an obvious first choice of Infrastructure as Code (IaC) tooling to support configuring the Streamdal server. We do plan to support additional IaC tools in the future.
The Terraform provider and documentation
Getting Started
Skip this section if you are already familiar with Terraform and simply copy/paste the provider block below.
- Install the Terraform command line tool
- Create a directory/folder to hold the config file and Terraform data. Let’s call ours
streamdal-config - Now create an empty text file called
main.tf. This is where we’ll put the Streamdal pipeline definitions, written in Hashicorp Configuration Language(HCL). - In the
main.tffile, we’ll configure a Terraform provider, which is used to take our HCL definitions and make the necessary API calls to the Streamdal Server:
terraform {
required_providers {
streamdal = {
version = "0.1.2"
source = "streamdal/streamdal"
}
}
}
provider "streamdal" {
token = "streamdal-server-token-here"
address = "streamdal-server-address-here:8082"
connection_timeout = 10
}- Now run
terraform initin your terminal to download the required provider. You should see output similar to the following:
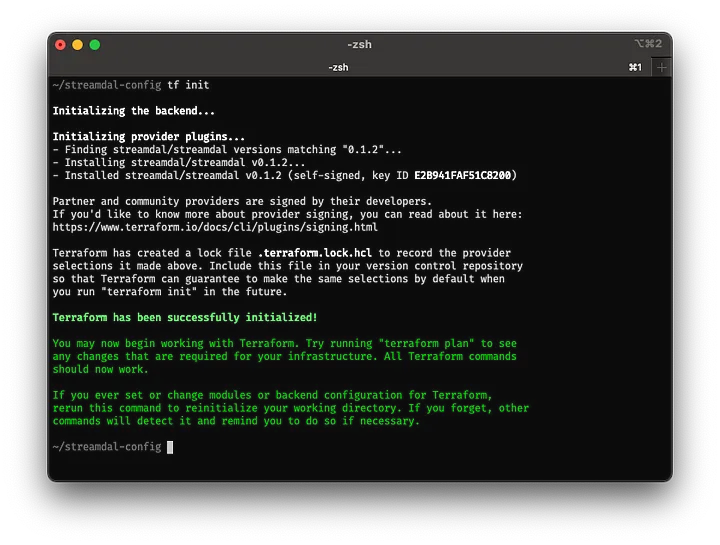
Output of Terraform init command
Now we’re ready to begin configuring our first pipeline and audience.
Setting up our first Pipeline
If you skipped the previous section, copy/paste the provider block into your .tf file.
We’ll start off with a basic pipeline definition that detects some PII (an email address) in a JSON payload and masks it.
We’ll use the pipeline resource to configure this:
resource "streamdal_pipeline" "mask_email" {
name = "Mask Email"
step {
name = "Detect Email Field"
# We specify abort conditions here since we don't want
# to continue with the second step if there is nothing
# to transform.
on_false {
abort = "abort_current" # No email found
}
on_error {
abort = "abort_current" # An error occurred
}
dynamic = false
detective {
type = "pii_email"
args = [] # no args for this type
negate = false
path = "" # No path, we will scan the entire payload
}
}
step {
name = "Mask Email Step"
dynamic = true
transform {
mask_value {
# No path needed since dynamic=true
# We will use the results from the first detective step
path = ""
# Mask the email field(s) we find with asterisks
mask = "*"
}
}
}
}Using the streamdal_pipeline resource, we’ll configure a pipeline named “Mask Email”. This pipeline has two-step blocks that define each step of the pipeline.
The first step uses the “Detective” module (detective{})to look for email addresses (type="pii_email")anywhere in the JSON payload it receives.
This type of matcher does not require any arguments (args=[]), and by omitting a path to a specific field (path=""), the entire payload will be scanned for any fields that have a value of an email address.
Now on to the second step…
We define another step{} block to create a second step. The important bit here is dynamic=true which indicates that we will use the results from the first step.
We will mask the email in the JSON payload, using the “Transform” module ( transform{}). Inside the transform{} block, we’ll configure a mask_value transformation, with an empty path="".
Note: We’re not specifying a path here because the previous step will pass any paths it detects as arguments to the second step.
Great! We’ve defined our first pipeline, and now we need to set up the “audience” to use this pipeline on.
Defining and Assigning an Audience
An audience is a definition that the Streamdal SDK uses to determine which pipelines to apply to a given call to .Process(). It consists of 4 pieces of data:
service_name— A name indicating the service you’re running the SDK in.component_name—This is used to indicate the source or destination of the data that you will be processing. Typically something likekafka,postgres,rabbitmq, etcoperation_name— Some kind of short descriptor indicating the operation that is processing the data.operation_type— Eitherconsumerorproducer
For demo purposes, let’s say we’re running the Streamdal SDK in our billing service, which consumes data from a Kafka topic in order to generate a sales report.
Using the streamdal_audience Terraform resource, we would define the audience as follows:
resource "streamdal_audience" "billing_sales_report" {
service_name = "billing-svc"
component_name = "kafka"
operation_name = "gen-sales-report"
operation_type = "consumer"
pipeline_ids = [resource.streamdal_pipeline.mask_email.id]
}For folks unfamiliar with Terraform, the value of the pipeline_ids field is dynamically populated by the result of the streamdal_pipeline resource we previously defined.
Now save your main.tf file, and we’ll create our pipeline and audience in the Streamdal server with the terraform apply command:
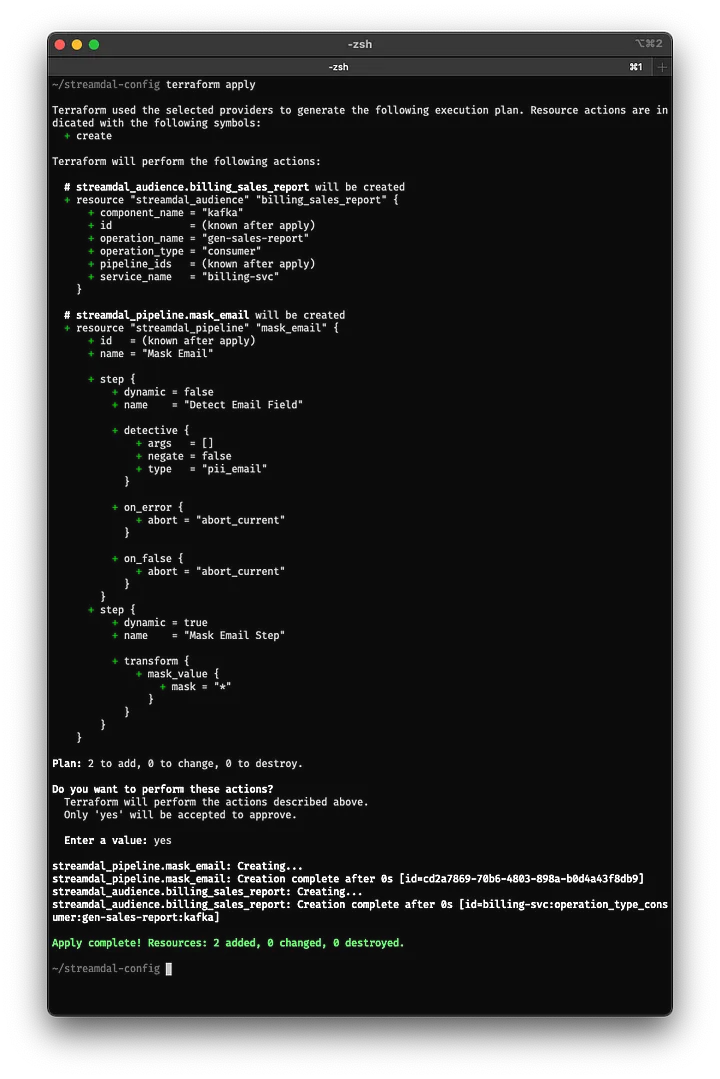
Output from Terraform apply command
Let’s open up our Streamdal console to see the results:
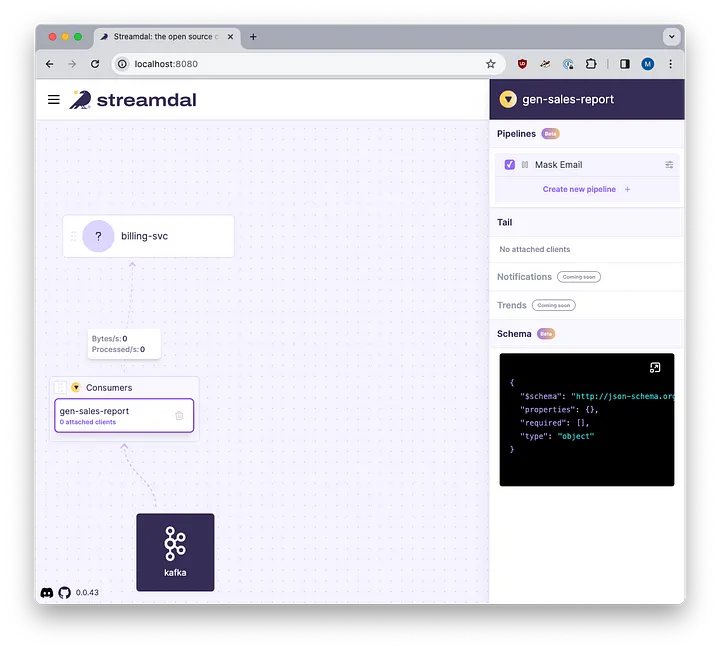
Streamdal console with our new pipeline and audience
As you can see, our audience is now defined and the “Mask Email” pipeline has been created and assigned to it.
We’re now ready to process data through our pipeline and prevent PII leakage!
Full Example
We have created a repository located at https://github.com/streamdal/blog-terraform-demo with the Terraform code from this article and also an example Golang app for you to run.

Want to nerd out with me and other misfits about your experiences with monorepos, deep-tech, or anything engineering-related?
Join our Discord, we’d love to have you!



