

The complexities and costs of data management are a huge challenge. Traditional setups involve a combination of data ingestion, storage, ETL processes, and analytics platforms, leading to increased operational costs, complexity, 85% project failure rate, many failure domains, and high turnover.
I can tell you from real-world experience that developer turnover is a real issue. As soon as one complex component gets built out someone on the team inevitably leaves. This is usually because the idea of maintaining such a project is very unappealing.
Data processing systems can create data silos, complicate compliance with security standards, and require extensive resources to manage effectively.
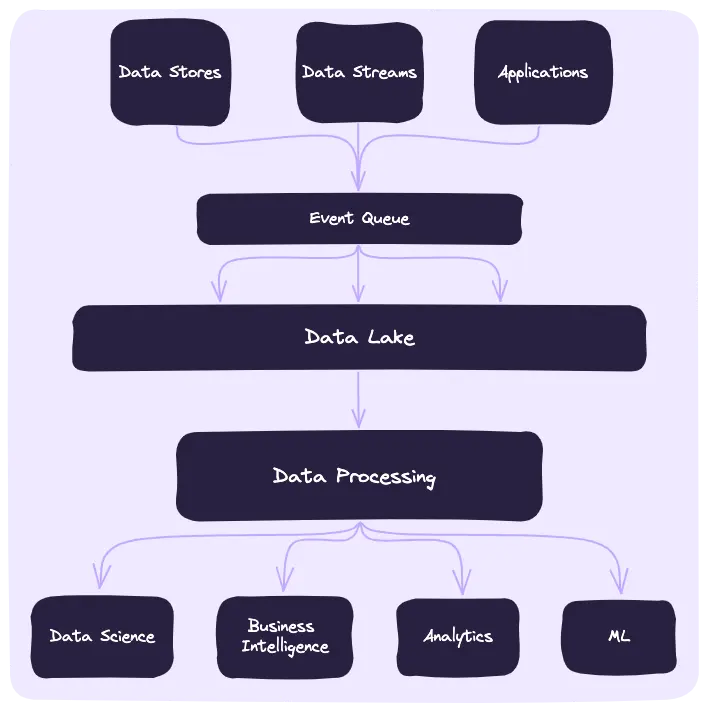
The diagram above illustrates a conventional data pipeline architecture. It starts with various sources like Data Stores, Data Streams, and Applications feeding into an Event Queue, commonly implemented using systems like Kafka.
From there, data flows into a Data Lake, such as Snowflake or Athena, where it often undergoes formatting and wrangling to fit the necessary structure. Subsequent stages involve numerous ETL (Extract, Transform, Load) jobs to process large data batches for specific use cases like Data Science, Business Intelligence, Analytics, and Machine Learning. Each of these stages tends to be resource-intensive and time-consuming.
This brings us to Streamdal which reimagines this workflow by integrating data processing directly into the codebase (Code-Native), streamlining and simplifying the entire data pipeline. This approach aims to bypass the expensive and time-consuming stages of traditional systems, offering a more efficient path for processing large swaths of data.
What is Streamdal?
Streamdal is an open-source code-native data pipeline platform that leverages WebAssembly (Wasm) to execute data transformations directly within the end user’s code via the Streamdal SDK. This approach enables developers to integrate pipelines directly into their code base. The diagram below illustrates a typical Streamdal workflow.
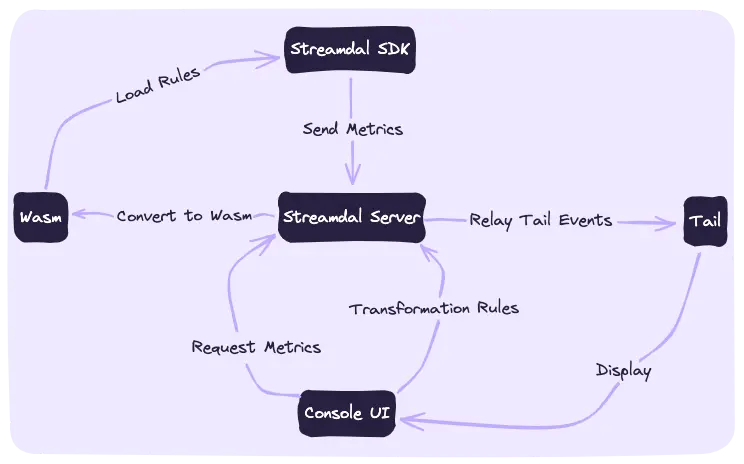
Streamdal Logical Flow
The Streamdal console pictured below allows developers to delegate the task of creating specific data transformations and rules to various teams. This approach spares developers from repeatedly diving into the codebase to update how data is managed. The UI is a massive time-saver, allowing teams to quickly visualize data flow across the organization and to create and attach pipelines to their chosen data streams with ease.
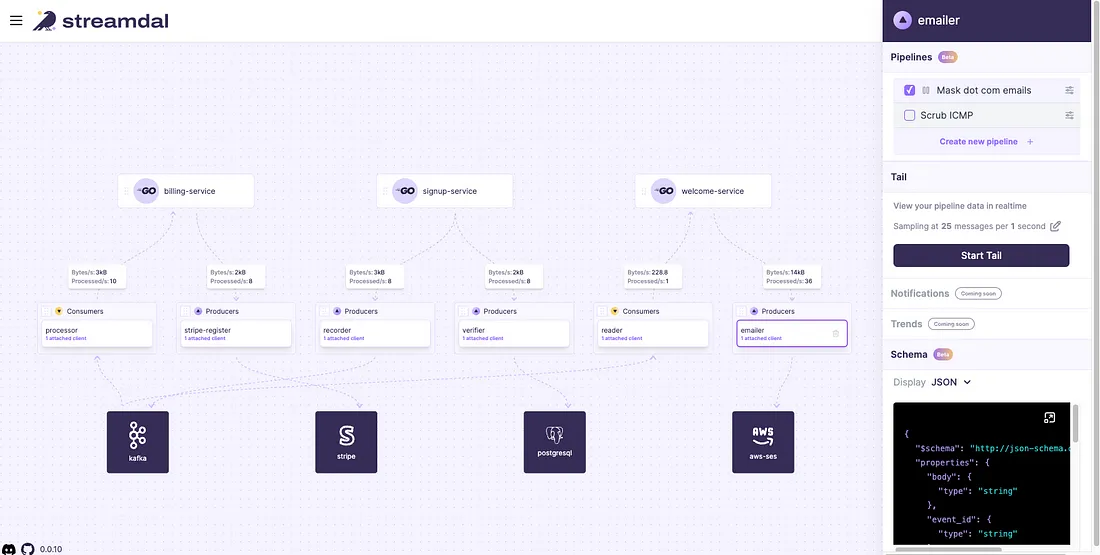
Streamdal Console
By moving data pipelines into the end-user’s application via Streamdal SDK, the process of creating and managing pipelines becomes simpler and more efficient. This enhances collaboration among developers, data teams, security experts, and BI professionals, leading to improved outcomes across the board.
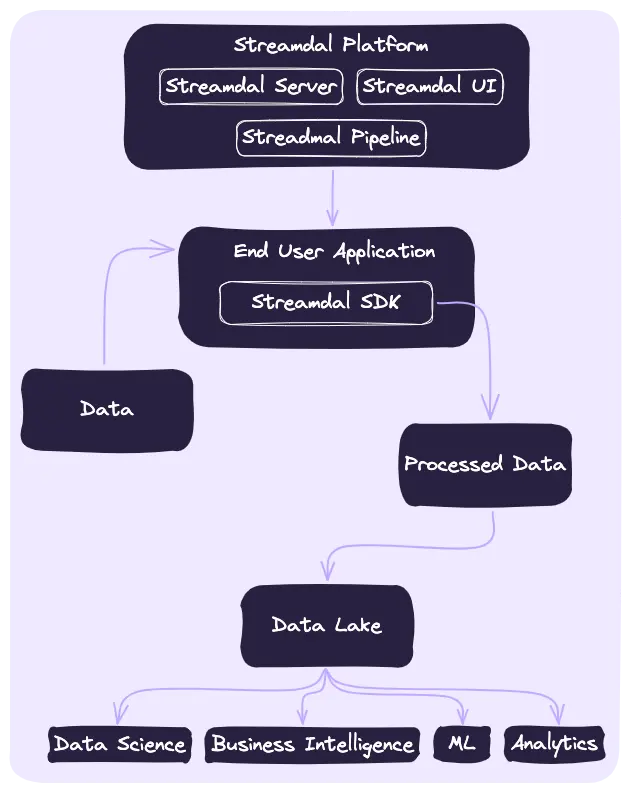
The diagram above illustrates the code-native pipeline workflow — at the core is the Streamdal platform, comprising the Streamdal Server and UI. These components work in tandem to manage and deploy WebAssembly (Wasm) rules, which are crafted within the Streamdal UI. Once defined, these rules are translated into Wasm and communicated to the end-user application through Streamdal’s SDK.
This setup is lightweight since the data processing workload is offloaded to the end-user application, minimizing the need for scaling the Streamdal platform itself.
The table below shows Streamdal transformation benchmarks. Wasm performs the transformation via the Streamdal SDK at sub-millisecond speeds. The performance that Wasm provides is a key feature that allows us to put data pipelines inline into the application itself.
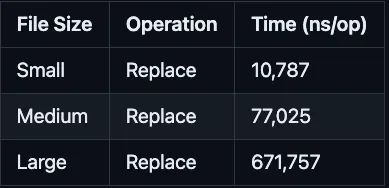
By processing data in real-time we immediately handle noise and complexity, which streamlines the flow of data into the data lakes and subsequent utilization for Data Science, Business Intelligence, Analytics, and Machine Learning.
Key Benefits of Streamdal for Data Management
- Direct Execution of User-Defined Transformations: The direct execution of Wasm transformations, provides a highly efficient method for data processing. Reducing the need for additional infra.
- Scalability and Low Overhead: The platform’s code-native approach allows for easy scaling by simply increasing instances of the end-user code, without the need for managing separate transformation services.
- Simplified Data Transformation: Streamdal reduces complexity by eliminating traditional ETL processes, streamlining the entire data transformation workflow.
- Empowerment of Teams: Developers, data teams, security, and BI teams can directly implement their transformations and rules, enabling greater control and customization.
- Efficient Resource Utilization: The reduction in dedicated resources for large ETL jobs leads to lower operational costs and more efficient use of infrastructure.
- Real-Time Data Monitoring: For applications where immediate data visibility is crucial, Streamdal enables real-time monitoring of I/O operations.
- Reduce Data Lake Cost: By transforming data in flight we can clean up any unnecessary data and transform the data before it hits our Data Lake. This greatly reduces the volume of data we are moving around in our Data Lake.
Conclusion
Code-native pipelines present a paradigm shift in data management by streamlining traditional resource-intensive data pipelines. In a data-driven world where agility and responsiveness are key, Code-Native pipelines stand out as an essential tool for any enterprise looking to optimize its data operations and drive meaningful insights.

Want to nerd out with me and other misfits about your experiences with monorepos, deep-tech, or anything engineering-related?
Join our Discord, we’d love to have you!


