

Pre(-r)amble
This is an “opinion piece”. For the actual “how-to” guide, read Migrating Repos on Github to a Monorepo.
I think monorepos are a waste of time, at best, and idiotic, at worst. Usually, it’s both.
Of course, there are exceptions but they are few and far between (ie. node, well-established stack, and/or single lang) and even in those cases, the PROs of the monorepo are up for debate.
And when it comes to CONs, there is not much I can add that hasn’t already been said in various articles, posts, and whatnot else, warning people about using monorepos… so I’ll leave you with my top 3 concerns 😄 : CI, access-controls, and versioning.
SIDENOTE: I get it. Writing hate posts about monorepos is pretty low-effort. But I promise, there’s more to this post than just “hurr-durr monorepos bad”!
With that out of the way, let’s get to the meat of this post:
Reasons for Moving to a Monorepo
Like clockwork, someone in your org will bring up monorepos and how they will solve all of your organizational problems.
It happens every year, in an architecture Slack channel, over lunch with platform folks, or worse, brought up by the VP of engineering. This will then be followed up by you writing up a three-page doc explaining why it is a really bad idea and what the actual cost of doing this will be. Rinse and repeat every X years.
But here’s the thing. After >20 years in tech, I think I have finally found the FIRST instance where the pain of migrating to a monorepo, is actually worth it (spoiler alert: it’s the open-source angle).
- Poor optics
- Poor UX / Poor DevEx
To understand why those are important to us, you first need to understand the software our company works on (to some extent).
Streamdal is an open-source, code-native pipeline engine — it allows you to do data wrangling application-side, without the need for traditional pipelines. The toolkit consists of many components and each one has its own repo. There’s a server, console, protobuf schemas, wasm artifacts, a Go SDK, Node SDK, Python SDK, docs, AND the main, “helper” repo.
Most importantly, many of the repos are interdependent — the console won’t work without a server, the server won’t work without wasm artifacts and the whole thing is useless without SDKs.
Finally, the “helper” repo serves as the main “entry point” repo — it is the main repo that we “advertise” and the main place that folks use to interact with the project. It contains install scripts, docs, some examples, and images and that’s about it.
And that is the first problem:
Poor Optics
What I mean by “poor optics” is that the “helper” repo does not change often. The only time it gets updated is to either fix the install script or add some docs. It doesn’t have any “code” in it, it’s just some shell scripts, maybe template and markdown files, maybe a Makefile and some assets.
This means that the “helper” repo will ALWAYS have fewer commits than the other repos.
A comparison of “activity & commits” on GitHub. On the left, is what the “helper” repo looked like before migration. On the right, is what the repo looked like post-migration to a monorepo.

And I don’t know about you but if I see a Last updated: 6 months ago on an Open Source project, I will already form an opinion about the “liveness” of it.
On top of that, because the repo only contains scripts, templates, and assets — Github will display the following in the “Languages” section for your flagship repo.
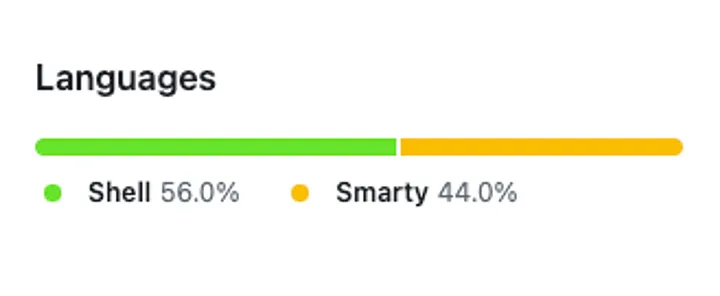
Yeah. Pretty lame. And not only from a vanity standpoint but I personally use the “Languages” section to quickly determine whether the project’s tech is “compatible” with my stack. As in, if my stack does not have any Java apps, should I start now?
For comparison, this is how this section looks like now that we have migrated to a monorepo:
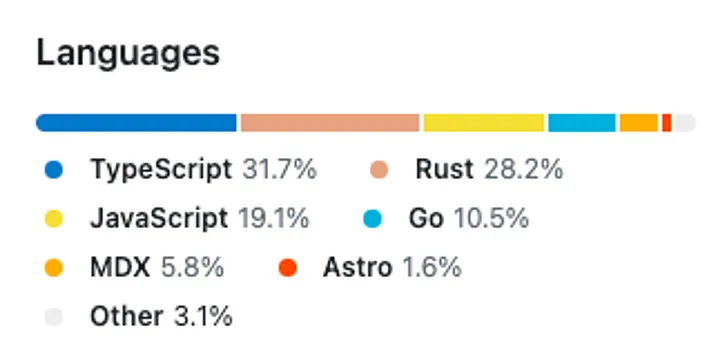
But besides optics, there is also the problem of:
Poor UX and DevEx
When you’ve got 10+ repos:
- How do you ensure that your users know which repo to interact with?
- If you want to report a bug and you don’t know if it’s caused by the
server,wasm,console, or some other component, where do you submit the issue? - How do folks contribute?
Community, collaboration, and support are all at the heart of an open-source project.
In our case, having 10+ inter-dependant repos makes it really difficult for users to figure out where they should submit issues, where (and how) to contribute to the project, or just figure out where to seek support.
Of course, you could keep contribution guidelines in all your README.md’s… hopefully they are all up to date! 😓
For this reason, it is crucial for an open-source project to provide users with a clear path for how to interact with the project.
A monorepo that contains ALL of the components that your project relies on, is a really good fit for a monorepo. I would argue to say that this single point alone might be worth it for some folks to migrate, but you do you.
Before Pulling the Trigger
Even if it seems like a monorepo might make sense for you, chances are, it still does not.
The pain involved in migrating to a monorepo is directly proportional to the maturity, size, and number of traditional repos that are monorepo candidates.
In other words, the more mature your project is, the more languages you have, the more repos you have, the more custom work you have done per repo… the more difficult it will be to perform the migration.
Here are some things to keep in mind before you pull the “migration trigger”:
- You will need to figure out the structure of the repo
— Does the usual
/apps,/libs,/docs, .. layout make sense? - You will need to figure out your versioning story — How are individual components versioned? Can you pull off a single unified version?
- You will need to update 👏 every 👏 single 👏 CI 👏 job
— Among many other pieces, you will need to “gate” the CI jobs — ie. if you are
/apps/serverand a PR was opened for/apps/client- you shouldn’t exec server CI tests and so on. - You will need to update every single
README.md— This is a “duh” but is a serious time-sink. All of the badges, links and in some cases the copy itself will need to be updated. - You will need to figure out if a larger repo size will pose a problem — Will your CI choke having to check out a 500MB+ repo every PR? Do you use multiple CI platforms? Is one massively slower?
Of course, this is not an exhaustive list but these are the immediate issues that I had to deal with when performing our monorepo migration. Most of these have been documented in the “How-to: Migrating to a Monorepo” article.
Conclusion
The monorepo addresses both of these problems perfectly. So with that, on Dec 20th, 2023, we (mostly) completed the migration from multiple repos to a single (sexy) repo.
None of it was particularly challenging — mostly annoying, time-sucking busy work.
The migration took ~1 week of actual hands-on time. It resulted in writing a migration script, running lots of sed and awk, and getting uncomfortably familiar with GitHub Actions.
And still, I think the PROs outweigh the CONs (at least for our very specific use case).
Here are the “before” and “after” pictures of the original repos VS monorepo 🥲
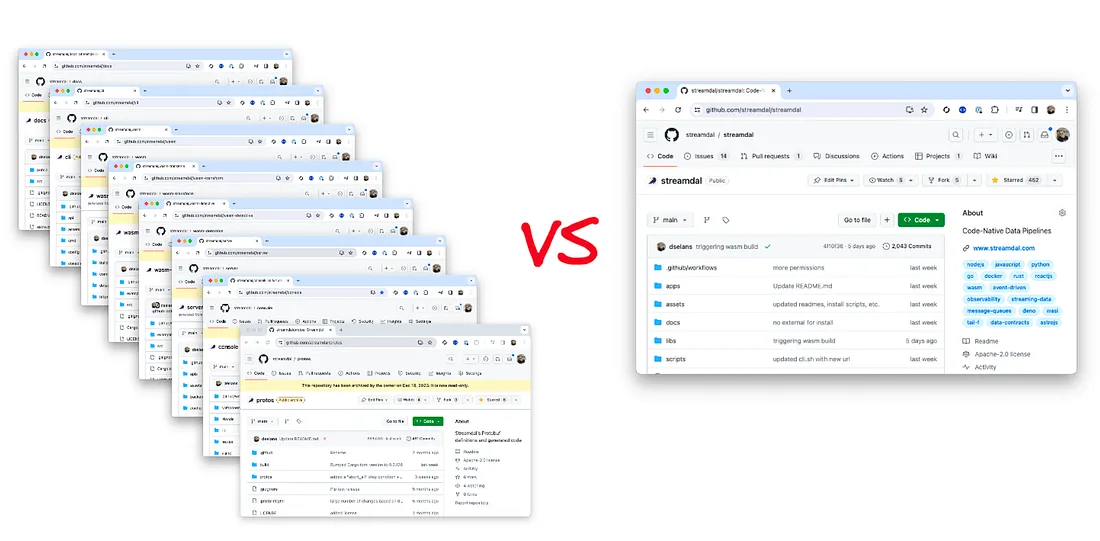
Rating
“Mostly Terrible”
…because it turns out monorepos can be useful, just very rarely.

Want to nerd out with me and other misfits about your experiences with monorepos, deep-tech, or anything engineering-related?
Join our Discord, we’d love to have you!



