

In this post, I will introduce you to a new concept called “Code-Native Data Privacy”. I will show you what it is, why it matters and most importantly, how it can simplify dealing with most data privacy, compliance and regulation-related issues.
What is it?
“Code-Native Data Privacy” is a modern approach to dealing with data privacy related issues.
Rather than standing up separate data infrastructure that is responsible for scanning, cataloging and masking data, the “code-native” way would instead have you embed the “scanning, cataloging and masking” parts, directly in your application code.
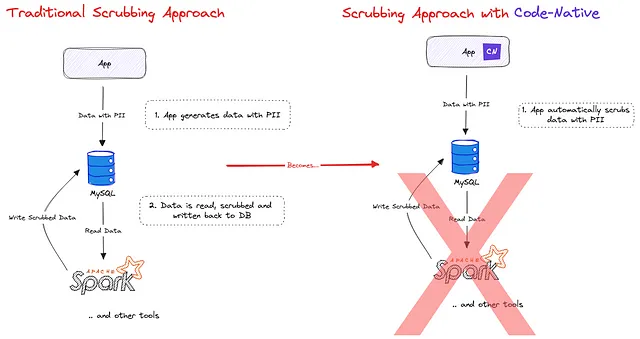
Traditional scrub approach VS scrubbing with “code-native data privacy”
What’s the point?
Up until now, organizations have been dealing with data privacy the same way for the last 15 years. And it’s inefficient, slow and really costly.
The traditional approach would look something like this:
- Begin by ingesting data from somewhere
- Then store it somewhere
- Then setup a process to scan the ingested data
- And then, if the scan finds something bad, transform the bad data
There are many things wrong here…
- For one, it is complicated — there are many moving parts and that usually means it’s hard to debug when things don’t work right.
- Besides that, it is going to be slow — “how slow” depends on how much effort you put into this system but it could be anywhere from 1 minute behind “real-time” to days or weeks.
- And, let’s not forget that until the data is properly cleansed, there’s a risk of violating customer privacy agreements or, even worse, falling out of compliance.
- .. and many more like source of truth issues, specialized engineering requirements, potential for network and/or infra-related problems or even organizational issues (who owns what).
That’s the gist of it and that’s basically how most companies deal with sensitive data. And there’s no shame in it. Trying to build something more sophisticated is a painful process — at the very least, you will need to level-up your engineering force, maybe even put together a dedicated data team and definitely need to setup additional infrastructure for this solution.
The point of “code-native data privacy” is to eliminate every single one of these CONs.
With “Code-native”, you get:
- 10x simpler data engineering effort
- 100x lower cost for data infrastructure
- 1000x faster data operations
.. and, most importantly ..
- Unlock new business enablement avenues
>>A Note on Business Enablement
“Code-native data privacy” has several really impressive benefits but the one I think that has a lot business impact is ”business enablement”.
What I mean by that is that “code-native” enables other parts of the business to make immediate, effective changes, without having to involve other parts of the organization.
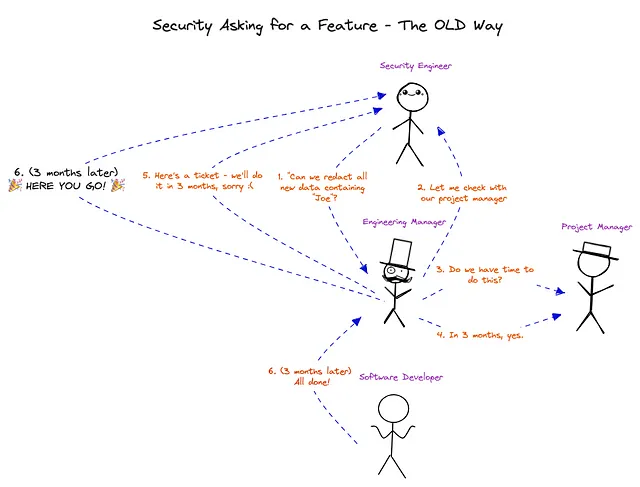
For example, before “code-native”, whenever your security team received word from compliance about needing to scrub or mask data with certain details, the process of getting the change implemented could take weeks or months.
The security lead would have to deliberate with a project manager, they would find the appropriate engineering manager, the engineering manager would then determine where to slot this work in and at some point, a TODO ticket would get created … and then a week or month later, compliance requirements would finally land.
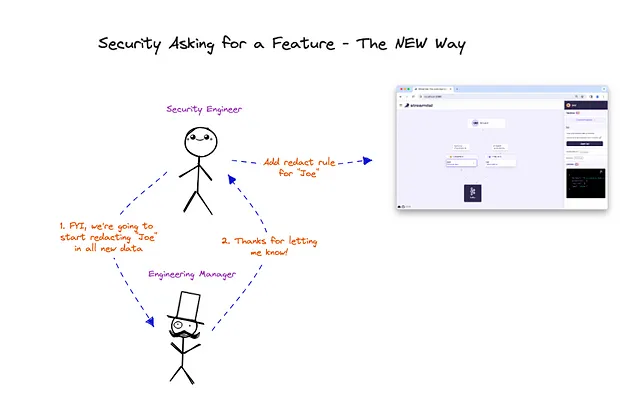
With “code-native”, the compliance department has been enabled to implement the changes via the provided Console WebApp, without having to involve anyone else.
The result — compliance is empowered, developers get time back which results in faster and higher quality deliverables.
To illustrate — this is how it usually looks like when security asks for a feature from devs:
And this is what it looks like with “code-native data privacy”:
What does it actually look like?
So far, I’ve been talking about these concepts mostly in the abstract so let’s get to the brass tacks — what does “code-native data privacy” actually look like?
“Code-native data privacy” is made up of three, distinct parts:
Library / SDK
At the heart of “code-native” is a light-weight software library / SDK (software development kit) that you inject into an application that performs data operations like reading user records from a database or writing invoices to some third-party service.
Data operations are referred to as “rules” and they can be anything as simple as “data must contain field XYZ” or scanning for PII and masking any detected fields in the data.
Think of this library as a “pre” and “post”-processor that your application will run after it has read data and before it writes data.
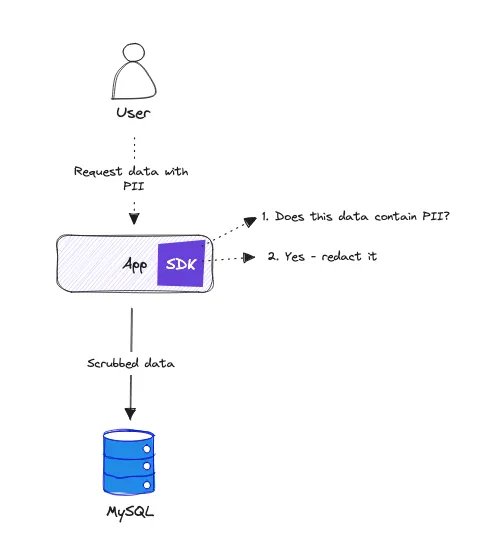
Example app instrumented with SDK validates (and redacts) data before it’s written to MySQL
Console / UI
But, business requirements change, compliance laws evolve and eventually, you will need to update your data scrubbing rules.
Rather than having to update the application itself with new rules, Streamdal comes with a Web Application we call the Console from which any team can configure new rules and push them to the libraries in real-time.
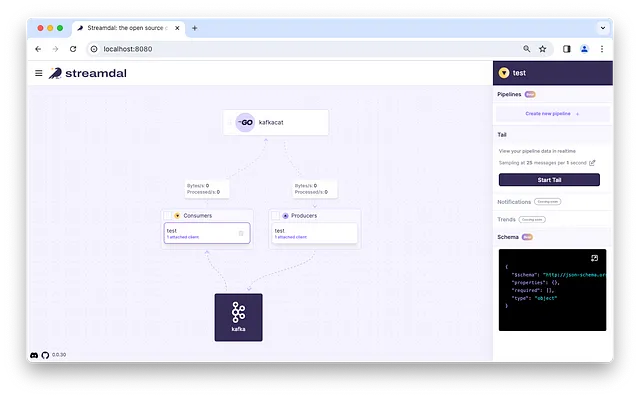
Console showing live view of instrumented “kafkacat” application
Server
And lastly, there is a Server component. The server is responsible for facilitating communications between the Console and applications using the Libraries/SDKs.
While the server is needed for sending updates to SDKs, it is not a critical component — it can experience outages and that won’t have any effect on the SDKs.
Most users would not have to ever interact with the server directly — it is intended to operate as a “set-it-and-forget-it” and requires very little baby-sitting.
You can read more about the server’s responsibilities here.
Zero-Network, 100% Local
Saving the best for last — “code-native data privacy” operates entirely locally.
As in, data operations executed by the libraries do not have to perform any network calls — everything is done locally, in real-time.
The result is 100x speed improvements, a dramatically simplified security story and less compliance-related headaches.
“Code-native data privacy” is completely free.
There’s no weird licensing, no “gotchas”. You can run it yourself right now, fork it or do whatever else you like with it, no strings attached.
To try it out for yourself, head to the “Getting Started” section in the main Streamdal repo or play around with the live demo.
Resources
- Main repository: https://github.com/streamdal/streamdal
- Documentation: https://docs.streamdal.com
- Live (read-only) demo: https://demo.streamdal.com
- Walkthrough: https://www.youtube.com/watch?v=gjHpSMWoWPs



